

今年3月底,Arm发布了全新的64位指令集ARMv9,号称10年来最重要的创新,IPC性能提升多达30%。5月25日晚间,Arm正式发布了最新一代的基于ARMv9指令集的处理器IP:超大核心Cortex-X2、高性能大核心Cortex-A710,高能效小核心Cortex-A510,分别取代现在的X1、A78、A55。这三款处理器IP均配备了三级缓存和丛簇共享单元DSU-110。
同时,Arm还发布了全新的Mali GPU IP——Mali G710/G510/G310,以及可以与 Arm CPU、GPU 和 NPU IP 无缝配合工作,使整个 SoC 解决方案的系统增强成为可能的互连网格网络IP CI-700和芯片网络IP NI-700。至此,Arm新的全面计算解决方案正式推出。
全新ARMv9指令集加持,Arm新一代Cortex CPU解析
Arm表示,自2020年启动了Cortex-X 自定义 (CXC) 计划以来,使定制和分化超越了Arm Cortex 产品的传统路线图,为合作伙伴提供了一种提供特定使用案例所需的最终性能的方法。而作为 CXC 计划的一部分,新一代Arm Cortex-X2 CPU则专为最终极的性能需求而设计,旨在最大限度地提高单线程和"突发"工作负载的性能,使其成为了目前性能最出色的基于ArmV9指令集的CPU。
Cortex-A710则是Arm的第一代基于Armv9指令集的大核CPU,它提供了性能和效率的最佳平衡。而Cortex-A510 CPU则专注于轻量级工作负载,效率是放在第一的,其将是应用极为广泛的Cortex-A55 CPU的继任者。
特别需要指出的是,Cortex-X2和Cortex-A710及Cortex-A510都可以集成在一颗SoC当中,但是,Cortex-X2和Cortex-A510都是纯64位的,不再兼容32位,而Cortex-A710则将继续支持OL0 AArch32。据了解,这是应中国客户要求特殊设计的,因为中国市场还有太多应用停留在32位。
所有这些 CPU 都可以通过全新的 DynamIQ 共享单元DSU-110 以不同的 CPU 集群配置结合在一起。这种可配置集群方法的多功能性满足了从高级智能手机和笔记本电脑到 DTV 和可穿戴设备等各种市场需求。这是Arm新的计算解决方案的支柱,该解决方案在多个消费设备市场和使用案例中提供不同级别的性能、效率和可扩展性的最新 Armv9 功能。
Arm高级副总裁兼终端设备事业部总经理 Paul Williamson 表示:“我们正致力于将 Armv9 技术引入到各个领域,以系统级设计最大程度地提高性能。安全和专用的处理能力,意味着基于 Arm架构的计算技术也将在智能手机以外的市场上获得领导地位,借助移动生态系统带来的巨大规模优势,在笔记本电脑、台式机、云等应用领域打造领先的解决方案。”
超大核心Cortex-X2
作为Arm最新的旗舰级的ARMv9指令集的CPU IP,Cortex-X2仅支持AArch64 64位指令而不再兼容32位,拥有全新层级的性能。

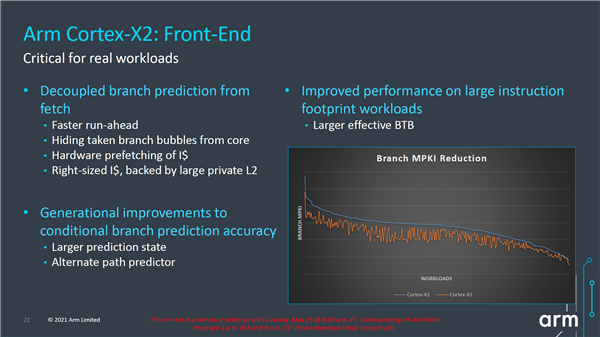
在前端方面,分支预测与预取单元解耦分离,从而可以在内核之前提前运行,从而减少预测错误,同时改进了分支预测精度,提升了大型指令负载的性能。
核心方面,流水线长度从11个指令周期减少到10个,其中分派阶段从2个周期减少到1个,这可是个非常大的变动。同时,乱序执行窗口增大了最多30%,244条增至最多288条,再加上指令压缩和绑定,实际还可以保存更多。FP/ASIMD流水线现在支持SVE2,矢量长度为128b,可以使得机器学习性能提升2倍以上。
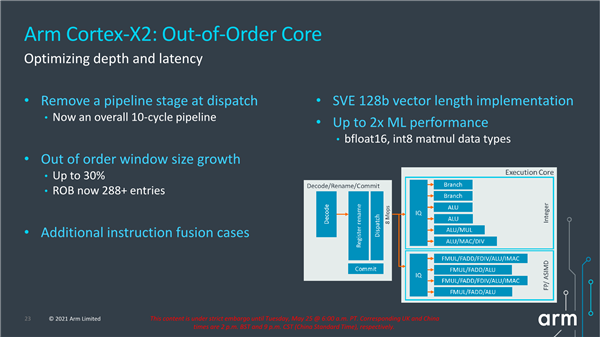
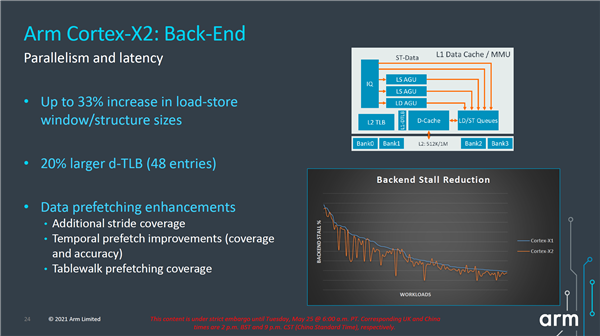
后端方面,载入存储窗口和结构增大了33%,可以提升内存级并行度,一级缓存d-TLB也增大了20%,另外增强了数据预取能力。
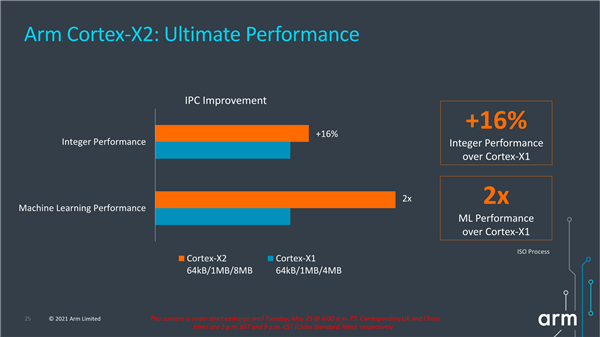
性能方面,ARM宣称Cortex-X2相比于Cortex-X1整数性能提升16%,机器学习性能则是其两倍。不过需要指出的是,Cortex-X2的三级缓存容量为8MB,比Cortex-X1增大了一倍。
此外,在能效方面Cortex-X2也是大幅优于Cortex-X1。
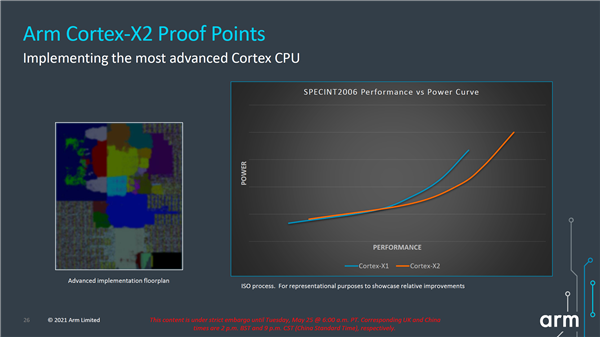
Arm表示,Cortex-X2 代表其性能表现最优的 Armv9 CPU,可跨高端智能手机和笔记本电脑。当结合最新的制程节点和适当的系统配置时,相比当今最好的 Android 旗舰智能手机,基于Cortex-X2的旗舰智能手机能够提供 30%的单线程性能改进。如果Cortex-X2被应用到笔记本电脑上,将能够提供比2020年主流笔记本电脑设备高出40%的单线程性能改进。

另外,通过 DSU-110 的扩展性能,单个 DSU 集群中可支持多达 8 个Cortex-X2 内核,并支持高达 16MB 的 L3 缓存。这意味着合作伙伴可以根据不同的市场需求调整 CPU 配置。
高性能大核心Cortex-A710
作为注重于性能和能耗平衡的高性能大核心,Cortex-A710基于ArmV9指令集,采用了新的微体系结构,通过提升单位面积能效的方式提高了性能。

在前端和X2一样改进了分支预测,精度更高,关键分支预测能力倍增。一级指令缓存TLB也从32条增至48条,不过macro-OP缓存仍然是1.5K(X2则是3K)。

相比Cortex-A78,Cortex-A710分支单元的宽度从6缩减到了5,提升了能效。在调度方面删除了一个管道阶段,现在10周期的管道,提升了调度的效率。

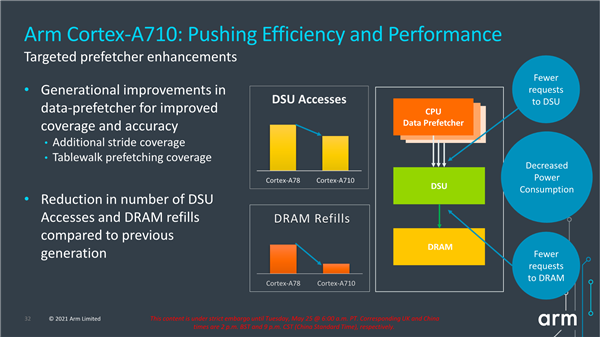
在核心设计上,Cortex-710也有针对性的提升了预取增强功能,包括采用新一代的数据预取器,提高了覆盖率和准确性,并且优化了核心与DSU的联系,核心与三级缓存、内存之间的延迟更低。Cortex-710拥有4MB二级缓存和8MB三级缓存。
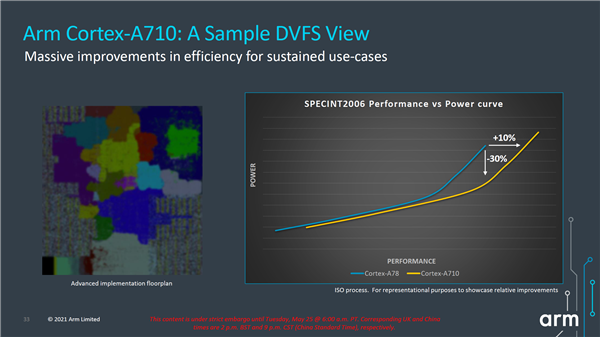
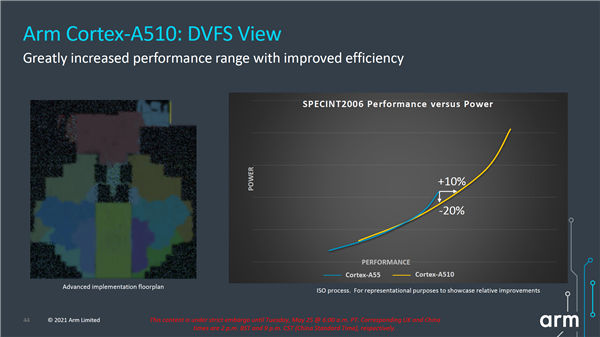
△Cortex-A710:DVFS视图示例,可大规模提高持续用例的效率
据介绍,而Cortex-A710 在与上一代Cortex-A78 CPU (ISO 工艺) 的相同功率下,性能提升了10%,而在相同的性能下,能效则提升了30%。通过这些性能提升,用户在智能手机(如AAA 游戏)上运行要求苛刻的应用程序时,增强了体验。同时还可延长所有移动设备的电池续航时间,并减少运行应用程序时的发热情况。

Arm表示,在大核CPU的设计中,需要平衡性能、功率和面积 (PPA)。新的 Cortex-A700 系列 CPU 是针对苛刻的工作负载确定持续性能的优先级,同时最大限度地延长电池续航时间。Cortex-A710 将我们的性能和能效提升到新的水平,在多种形式因素之间提供不折不扣的可扩展性和性能。这意味着Cortex-A710可以瞄准广泛的消费类设备,从高级智能手机和笔记本电脑到智能家居设备和智能电视。
高能效小核心Cortex-A510
Cortex-A510继续使用3宽度的顺序执行架构,但也借鉴了X系列在分支预测、数据预取方面的一些技术,继续提升能效。

Cortex-A510还引入了合并核心(merged-core)的新设计,可以使得两个核心可以组合成一个复合体,每个簇可以有多个复合体,并且二级缓存、二级TLB和向量数据路径在复杂系统中可共享,这提高了单位面积效率,配置的可扩展性大大提升。

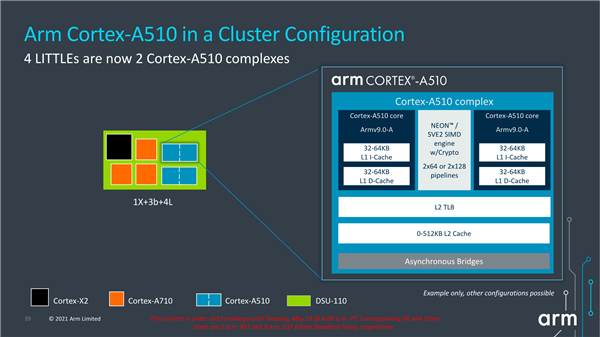
需要指出的是,Cortex-A510每个核心则有自己完整的前端、核心、整数后端、一级缓存,只是共享了二级缓存(最大512KB)、FP/NEON/SVE流水线。
如果客户喜欢,也可以继续使用独立核心,但是面积效率会低一些。

前端设计方面,Cortex-A510具备128位预取流水线,每个时钟周期可以拾取4条指令,解码器宽度从2增加到3。
分支预测没有透露细节,只是说顶级的多级设计,另外一级缓存可以32KB或者64KB。
核心方面,可以设置2个64位流水线或者2个128位流水线,后者是Cortex-A55的两倍。

尽管是顺序架构,Cortex-A510后端依然加宽包括3个整数ALU单元、一个复杂MAC/DIV单元、一个分支派送端口。
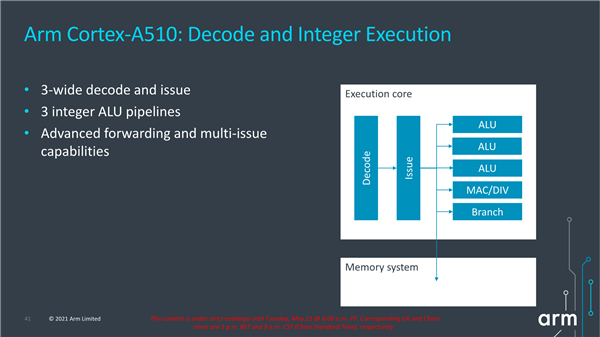
在载入存储方面,Cortex-A510相比Cortex-A55有了极大的改进,从载入存储流水线,变成了2个载入+1存储流水线,每时钟周期可执行的载入数量翻了一番,另外流水线宽度也从64位提升到了到2×128位,使得总的载入带宽达到了Cortex-A55的四倍。

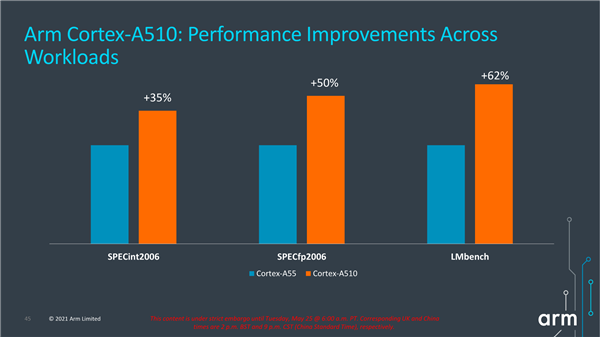
Cortex-A510还配备了32KB一级缓存、256KB二级缓存、8MB三级缓存,对比Cortex-A55的32KB一级缓存、128KB二级缓存、4MB三级缓存有了大幅的提升。具体到性能方面,Arm公布的数据显示,Cortex-A510相比Cortex-A55提升幅达到了35-62%。

Arm表示,Cortex-A510是其四年来首款高效小核心,核心性能比Cortex-A55提升了超过35%,机器学习性能提升超过3倍。这种性能已经接近几年前的上一代大核CPU,这意味着在切换到大核CPU 之前,更多的工作量可以通过小核CPU来完成,在更大的内核上运行所需的计算工作量更少,使得整体的续航可以进一步提升。
另外,作为高效小核心,Cortex-A510在能效上相比Cortex-A55也有了20%的提升,这将使得设备续航能力进一步提高。而这也得益于Cortex-A510支持将两个Cortex-A510组合为一个复合体,每个 CPU 集群可以包含多个复合体。其结果是在更高的性能点,提高单位面积效率。合并的核心微结构还为不同消费设备的可扩展性提供了广泛的配置范围。
Arm称,Cortex-A510将成为智能手机、家用和可穿戴设备的理想之选。
共享单元DSU-110
众所周知,在之前的Arm的CPU集群当中,大小核的搭配主要是基于DynamIQ的big-LITTLE架构,而Arm针对基于ARMv9指令集的DynamIQ CPU 集群,引入了新的共享单元DSU-110。它将支持将不同的ARMv9 CPU 结合到不同的集群配置中,这些配置可解决不同 PPA 节点的不同细分市场需求。
正如前面提到的,最大的 CPU集群可配置8个Cortex-X2:但是,针对不同的市场需求,有一系列不同的 CPU 集群配置。例如,4个Cortex-X2 和4个Cortex-A710 的高性能 CPU 配置,可针对高级笔记本电脑设备。一个Cortex-X2+3个Cortex-A710+4个Cortex-A510,可以支持高端智能手机。当然,还有更多的其他的组合。
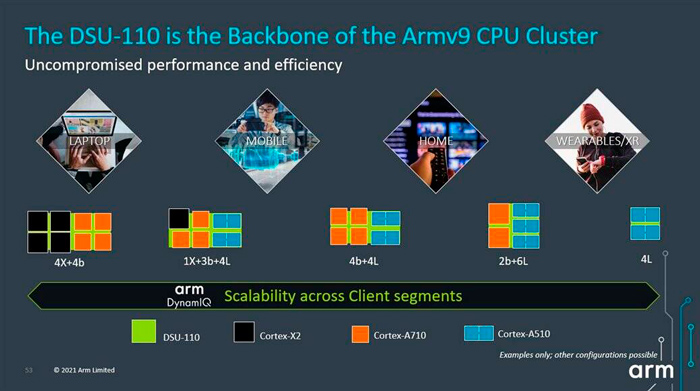
而引入的共享单元DSU-110 的微结构可大幅提高带宽(高达 5 倍)、改进多处理器性能以及应对所有设备市场的可扩展性,并降低功耗。DSU-110 的更高频率功能带来了带宽、延迟和功率改进的组合,可围绕不同的要求进行调整。例如,这可以使带宽更高、延迟更低或在现有频率下降低功耗。多处理器性能改进得益于更大的 L3 缓存(高达 16MB)和最多 8 个 Cortex-X2 内核的支持。
在续航方面,DSU-110 可减少 CPU 集群的电源泄露,以改善设备上的“使用天数”。即配置为更高的带宽,可使得其比上一代的功耗更低。此外,当 DSU-110 部分断电时,低强度工作负载仍然可以运行,这是“熄屏工作”场景下的理想选择。DSU-110 还通过新的集成电源策略单元 (PPU) 和多种节电模式带来了先进的电源管理功能。
机器学习性能大幅提升
随着 ML (机器学习)性能成为所有消费设备的要求,Arm 的Cortex-CPU 越来越多地用于 ML 计算。这主要是因为它们普遍存在且易于编程。而在此前DynamIQ CPU 推出之时,Arm就特别强化了ML的能力。
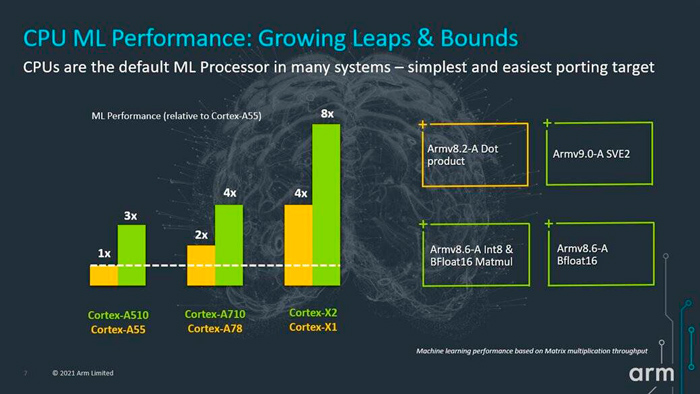
而对于全新的ARMv9 CPU,Arm则引入新的功能,如支持 BFloat16 格式、Int8 和 BF16 和 SVE2 的矩阵乘数指令。这些使较新的使用案例在性能上得到改善。例如,由于新的马特穆尔指令支持,Cortex-X2的ML性能将比Cortex-X1提高了一倍。与Cortex-A78相比,Cortex-A710也是如此。而与Cortex-A55相比,Cortex-A510的ML性能则达到其3倍。
安全性
随着越来越多的消费设备以更先进的计算能力进入市场,并因此产生也产生了很多针对这些设备的攻击,安全威胁变得越来越复杂和普遍。与此同时,通过这些始终连接的设备获得的个人内容和数据的数量和价值也在不断增加。因此,Arm认为必须提供可信赖且易于部署的安全功能,使合作伙伴能够构建更安全的 SoC,从而为最终用户提供安全可靠的数字体验。
作为全面计算解决方案的一部分,Arm正在提高安全性标准。在 Armv9 架构中,Arm构建了一系列新的和现有的安全功能,以改善所有消费细分市场的安全性。这意味着Arm的合作伙伴可以从软件投资到安全措施实现更好的价值,从而找到更标准化和可扩展的安全解决方案,从而应对多种安全挑战。

Arm引入的Secure-EL2 为受信任的服务提供了标准的安全隔离机制,并使维护设备安全性的方法更加简单。内存标记扩展 (MTE)可检测和防止整个生态系统中的记忆安全漏洞,为一系列 Arm 合作伙伴提供性能和上市时间优势。包括从解决 SoC 中错误问题的硅供应商,到使用 MTE 设备查找自己的缓存溢出和代码堆损坏的 OSV 和应用程序开发人员。Arm表示,其已经与谷歌合作,在Android上采用MTE后,其项目团队表示,70%的严重安全漏洞是内存安全问题。
Arm还通过两个新的内置功能——指针身份验证 (PAC) 和分支目标标识符 (BTI) 来解决控制流完整性问题。这两个硬件机制能够有力地防止返回导向编程 (ROP) 和跳向编程 (JOP) 攻击。根据Arm对启用这两个功能的研究,Glibc 中攻击者可用的小工具数量减少了约 98%,而代码大小仅增加了 2% 左右。
Arm还通过在 NEON 和 SVE2 空间中添加加密指令进一步扩展了现有的安全支持。这加速了与各种消费设备相关的加密算法。最后, Armv9 CPU 支持使用微型架构内置防御的投机障碍,可以减轻侧通道攻击。
Arm全新GPU IP:Mali-G710/510/310
除了全新的ARMv9 CPU IP之外,Arm此次还推出了全新的Mali-G710 、Mali-G510和Mali-310 GPU。
据介绍,在过去的一年里,Arm的合作伙伴已经出货了超过 10 亿颗Mali GPU。这也是Arm连续第五年实现这一里程碑。现在,Arm推出全新一代的Mali GPU系列IP,希望能够继续引领移动GPU市场。
Mali-G710
Arm表示,Mali-G710 GPU是Arm有史以来性能最强的GPU,主要面向希望获得更好、更长时间的娱乐体验高端智能手机,可提供强大的图形计算密集型体验,如AAA级高保真度游戏。
与上一代Arm Mali-G78 (ISO 工艺) 相比,Mali-G710 在性能上提升了20%、能效提升了20% 和机器学习 (ML)性能提升了35%。

而手机游戏市场正是Mali-G710 GPU的一大焦点。游戏市场情报机构Neozoo估计手机游戏收入达到767亿美元。这比2019年增长了12%,目前超过了PC和主机游戏收入。移动游戏体验也变得越来越复杂,更多的高级 AAA 级游戏体验将进入移动端。智能手机需要匹配更大的游戏复杂性,通过以下增强功能实现这些体验:
- 更好的光线效果
- 更复杂的几何形状、阴影、纹理和粒子效果
- 高级后处理效果
- 更高的刷新率,以获得更流畅的游戏体验。
基于此,Arm Mali-G710 带来了一系列新的"改变游戏规则"功能和技术,满足了高端智能手机设备对游戏增强的需求。这些新功能还能够提升性能、能效和 ML。
首先,Mali-G710 引入了新的命令流前端 (CSF) 是一个重大变化。CSF 使Mali GPU 符合现代 API(如 Vulkan)的要求以及未来的移动游戏内容趋势。CSF 的最大好处之一是它减少了 CPU 必须执行的工作量。这反过来又降低了需要提供给 CPU 的电力预算,使 GPU 能够执行更多任务。
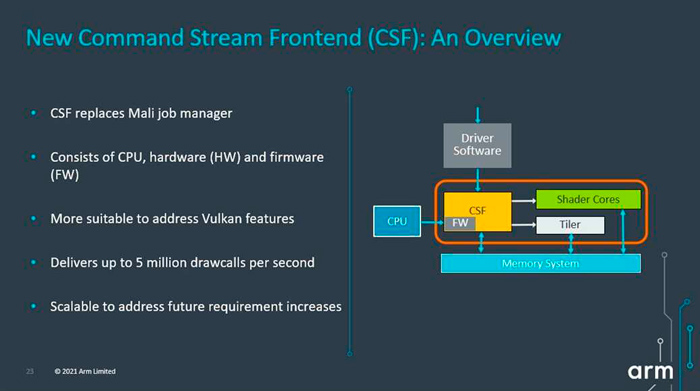
其次,Arm还为Mali-G710带来了经过大量重新设计的着色器核心,以增加性能密度。同时Mali-G710拥有可配置的内核数量,从 7 个核心扩展到了多达 16 个核心,虽然这比Mali-G78 的可支持的内核数量(24 个核心)要少,但是Mali-G710核心更大,性能更出色,更节能。
具体来看,Arm在Mali-G710的每个着色器内核中添加了第二个执行引擎,使每个内核的计算能力翻倍,并更有效地利用共享资源。可使整个(ISO 流程)节能 20%。这有助于在高级 GPU 中提供 Arm 有史以来最高的能效,从而延长目标设备的电池续航时间。对最终用户,这意味着他们可以“做更多”和“玩更多”。
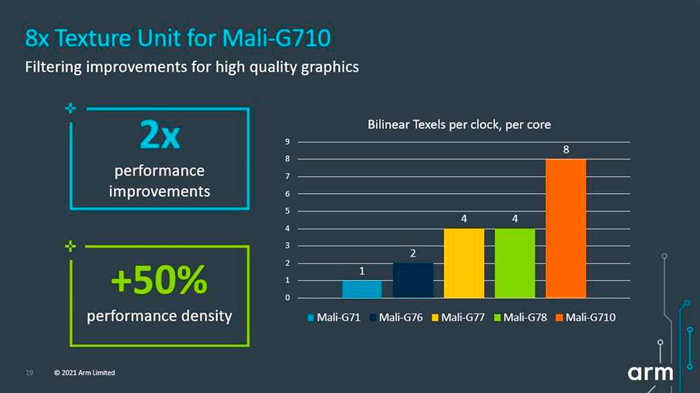
除了在执行引擎和着色器核心上进行大量工作外,Aalim还重新设计了纹理单元。与上一代相比,Mali-G710的纹理性能翻了一番。但是,性能翻倍不会花费两倍于该区域的费用。这也意味着Mali-710的图形性能增加了一倍,而芯片面积只增加了50%,这意味着性能密度显著提高。增强的纹理功能尤其适用于复杂的游戏场景。
与每一个高级 GPU 一样,Arm也为Mali-G710带来了更多的 ML 提升(35%)。因为 GPU 现在用于各种不同的 ML 相关任务,特别是图像增强和再培训。这为智能手机设备带来了先进的用户体验,如新的摄像头和视频模式,以及安全增强功能。
Mali-G610
Mali-G610继承了Mali-G710的所有特性,如新的CSF,但它的可配置着色器内核(1-6)较少。这也为价格较低的次旗舰智能手机带来了近乎旗舰级的性能,有助于将高级使用案例(如高性能 AAA 游戏)带给更广泛的开发人员和消费者。许可 Mali-G710 的合作伙伴可以重复使用该IP,以快速将最新的 GPU 功能带给子高级细分市场的更多受众。

Mali-G510和Mali-G310
Mali-G510 GPU代表了性能和效率的完美平衡,主要面向中端智能手机、高级 DTV、机顶盒 (STB)和 Chromebook。
最后,Mali-G310则是Arm最高效的GPU,与上一代Mali-G31 GPU相比,性能有了巨大的提升。Mali-G310也是Arm有史以来首款基于Valhall架构的高效 GPU,主要面向入门级智能手机、入门和中端 DTV 和 STB、智能手表以及AR 和 VR可穿戴设备。
与上一代 GPU 相比,Mali-G510 和 Mali-G310 带来了显著的性能提升,同时提供可减少带宽的功能,从而进一步提升性能和降低功耗。
具体来看,与上一代Arm Mali-G57相比,Mali-G510实现了性能和效率的完美平衡,性能提升了100%、电池续航时间提升了22% 和 ML性能提升了100%。

同时,与上一代 Mali-G31 相比,Mali-G310纹理性能达到了其6倍、Vulkan 性能达到了其4.5倍、 Android UI 内容性能则达到了其2倍。这些巨大的改进是由于Mali-G310是有史以来第一个基于Valhall架构的高效 GPU。它还受益于Arm过去三代 GPU 的微观结构变化。从本质上讲,Mali-G310 旨在以最小的区域成本提供最高的性能。

综合来看,Mali-G510 和Mali-G310 的显著性能提升,得益于 GPU 采用了Mali-G710 的一些特性和增强功能,然后针对不同的性能、功率和区域 (PPA) 需求来进行优化。
比如,与Mali-G710最大的区别是着色器内核的数量,Mali-G510有2-6个可配置的着色器内核,Mali-G310则有一个。但是,后两者都继承了 CSF、重新设计和附加执行引擎以及Mali-G710 重新设计的纹理单元。
此外,Mali-G510 和Mali-G310 还支持了其他功能,以满足广泛的设备。例如,Mali-G510 提供更好的 HDR 支持、Arm Frame Buffer Compression (AFBC) 未压缩缓冲器和用于减少带宽的新的Arm Fixed Rate Compression (AFRC)。同样,Mali-G310 也可提供更好的 HDR 支持和 AFBC 未压缩缓冲区格式。AFRC 是Mali-G310 的可选功能,同时还可提供用于 AR 和 VR 提升的 foved 渲染(Mali-G57 的一个功能)。
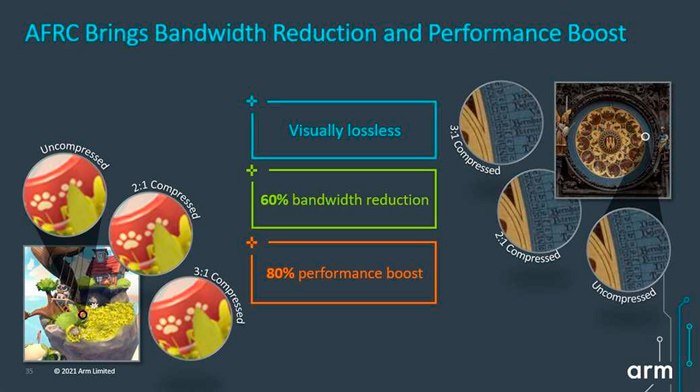
值得一提的是,Arm将视觉上无损的固定费率压缩(AFRC)引入,可提供出色的视觉质量,具有高固定压缩率。在此之前,Arm主要是采用AFBC来提供无损压缩,但是要无损,则无法保证内存带宽的减少。而新的 AFRC 技术保证了带宽和内存占用量的减少,具体取决于压缩水平和内容类型,最低区域成本。这转化为性能提升和节能,因为向 DRAM 读取和编写的数据较少。仅使用 AFRC就使带宽减少 60%,同时使峰值性能增加 80%。这反过来又降低了内存子系统和 DRAM 的成本,从而降低了 SoC 本身的成本。
上述功能允许每个 GPU 具有不同的配置选项,以解决特定设备以及不同的性能和效率需求。这也意味着两个 GPU 的可扩展性更高。Mali-G510有10种配置选项,而Mali-G310则有5种配置选项。事实上,Mali-G510 的产品配置和粒度是马里 GPU 有史以来最高的。每个配置可解决不同的区域和性能点,以及不同的计算和处理需求。
Arm表示,2021 年将为所有细分市场引入新的GPU。该套 GPU 涵盖广泛的消费设备、广泛的娱乐和生产力体验,具有针对不同性能和效率需求的灵活性和可扩展性。Mali-G710 继续推动高级性能,使移动游戏终端的 AAA 游戏体验更加普及,而Mali-G510 和 Mali-G310则可帮助客户在各种低成本消费设备上提供更先进的用户体验和图形。我们相信,这种广度的 GPU 能力和无与伦比的灵活性将继续保持Mali GPU作为世界第一移动图形处理器的市场领先地位。
CoreLink CI-700/NI-700
Arm此次还针对全新CPU/GPU IP,推出了最新的互连网格网络IP CoreLink CI-700和芯片网络IP CoreLink NI-700,他们可以与 Arm CPU、GPU 和 NPU IP 无缝配合工作,使整个 SoC 解决方案的系统增强成为可能。CoreLink CI-700 和NI-700 为新的 Armv9-A 功能(如内存标记扩展 (MTE) 带来了硬件级别支持,并支持增强安全性、改进带宽和延迟。
具体来看,CoreLink CI-700是一种可配置的连贯互连,与 ARMv9处理器和最新的 Arm 技术一起设计,可实现完全优化的总计算解决方案。每个 CoreLink CI-700 可跨总计算解决方案扩展,用于高级、性能和效率层。这些解决方案提供不同级别的性能、效率和可扩展性,可在多个消费设备市场提供专业计算。CoreLink CI-700 的可扩展性意味着它可以支持低功耗互连实现,从 1GHz 一直到 5nm制程高达 2GHz 的高性能实现。
CoreLink NI-700 是一种灵活的分组网络片上互连,用于高带宽加速器(如 GPU 和 NPU)以及 SoC 其余连接。分包可使布线减少 30%,从而简化物理设计。芯片网络 (NoC) 互连还采用最新的 Arm 架构功能和 AMBA 接口标准。这可提高性能、可靠性和虚拟化。此外,先进的模布支持能够更快地设计、配置和实施复杂的 SoC,从而改善系统性能,减少路由拥塞和区域。
合作伙伴证言
King CTO Steve Collins:“Arm新的全面计算解决方案使得处理器和系统设计向前迈出的一大步。
这种全面计算方案将带来性能、功率效率和我们玩家将重视的一系列功能。我们期待利用新的 IP 为我们世界各地的玩家提供更丰富的游戏体验,提供更高的保真度图形和游戏性能,帮助 King 让世界更加俏皮。
联发科CTO Dr. Kevin Jou:“移动设备,比如智能手机、平板电脑、电子书,已经改变了我们的社交、工作和学习的方式。Arm 的全面计算解决方案为移动领域带来了令人兴奋的新进展,提高了计算性能,提高了系统效率,并为未来的设备提供了更强的安全性。我们期待继续与 Arm 合作,提高下一代用户在娱乐、教育和生产力方面的体验。”
三星电子CTO Dr. Kevin Jou:“智能设备已成为我们生活的数字扩展,而这需要依赖于性能、效率和安全性。凭借 Arm 基于其最新的 Armv9 架构和增强的领先合作伙伴关系的全面计算解决方案,三星的系统 LSI 业务和 Arm 将为下一代移动平台开辟新的可能性,我们对此感到兴奋,这将通过我们未来的技术为用户体验带来变革。”
Unity vice president of Platforms, Scott Flynn:“我们很高兴能支持 Arm新的全面计算解决方案。这种新解决方案是向前迈出的一大步,为基于 Arm 的设备提供更好的性能创造了基础。我们的软件和基础硬件之间的紧密联系将帮助 Unity 创作者进一步推动他们的游戏和应用程序,带来更多身临其境和令人惊叹的体验。”
Zoom Head of Hardware Partnership, Eric Yu:“过去一年,我们推动了技术解决方案,改变了人们的互动方式。我们现在要求在平台一级更加需要安全和情报。基于 Armv9 的全计算解决方案具有增强的安全功能和更高的性能,将为使用 Arm 技术的下一代智能手机和笔记本电脑设备提供更无缝的沉浸式体验。”
编辑:芯智讯-浪客剑







