
早在2022年2月时,当英特尔宣布其“Falcon Shores”项目以构建混合 CPU-GPU 计算引擎时,该项目允许在单个插槽中独立扩展 CPU 和 GPU 容量,英特尔似乎正准备用混合计算机与竞争对手英伟达和AMD正面交锋,英特尔将其称之为XPU,AMD称之为APU。
英特尔所采用的是方法将CPU和GPU芯片的可变组合放入Xeon SP插座中,该插座具有完全相同的主存储器和芯片之间的极低延迟链接,可以进行比Xeon SP中的AMX矩阵数学单元所能处理的更复杂的人工智能推理,以及比AVX-512矢量单元中可能进行的更高的HPC浮点处理客户求助于Max系列中延迟更高的独立GPU,或者实际上是来自Nvidia或AMD的独立GPU。
当英特尔加速计算系统和图形业务总经理 Raja Koduri 宣布时——在今年 3 月 Koduri 离开英特尔后该业务已停止——英特尔承诺 Falcon Shores将在X86插槽中提供每瓦5倍以上的性能,以及超过5倍的内存带宽和容量,即所谓的“极限带宽共享内存”。

Falcon Shores 原定于 2024 年推出,外界普遍预计它将直接与未来的“Granite Rapids”Xeon SP 使用的相同“Mountain Stream”服务器平台。推测英特尔可以做一些疯狂的事情,比如给 GPU 一个仿真层,让它看起来像一个大而胖的 AVX-512 矢量数学单元,以简化编程。
到今年3月,随着Koduri离开英特尔,该公司开始倒退,不仅在Xeon SP 插槽内提供看起来像五种不同的CPU-GPU小芯片混合,但也扼杀了“Rialto Bridge”对“Ponte Vecchio”Max系列GPU的推动作用,该GPU将在阿贡国家实验室的“Aurora”超级计算机中完成2 exaflops峰值的大部分处理。当时有传言称,第一台Falcon Shores设备将于2025年问世,而且上面只有GPU芯片,这使得该设备基本上是一个独立的GPU替代品,代替了 Rialto Bridge取代了Ponte Vecchio。Rialto Bridge之所以被取代,这是因为英特尔希望在其路线图上采用每两年更新一代 GPU 的节奏——这是合理的,因为这正是 Nvidia 和 AMD 正在做的事情。
在最近于汉堡举行的 ISC23 超级计算会议上,英特尔阐明了其对 Falcon Shores 的意图,确认该设备不仅将成为纯 GPU 计算引擎,而且混合 XPU 的时机还不成熟。
英特尔超级计算集团总经理 Jeff McVeigh 在 ISC23 活动的简报中解释说:“我之前关于将 CPU 和 GPU 集成到 XPU 中的推动和强调还为时过早。” 坦率地说,McVeigh 可能要为 Koduri 甚至 Jim Keller 做出的决定承担责任,Koduri 两年多前从英特尔离职成为 AI 初创公司 Tenstorrent 的首席执行官,现任首席技术官。
“原因是,”McVeigh在解释中继续说道,“我们觉得,我们所处的市场比一年前想象的要充满活力得多,所有的创新都围绕着生成式人工智能大语言模型。虽然其中大部分都在商业领域,但我们看到,这在科学领域也得到了更广泛的采用。当你身处一个工作负载变化迅速的充满活力的市场时,你真的不想让自己走上一条固定CPU与GPU比例的道路。你不想固定供应商,甚至 X86 和 Arm 之间使用的架构——哪些是最好的,因为它将允许灵活性,允许它们之间的良好软件支持——与你在成熟市场中相比。当工负载固定下来,当你对它们非常清楚时,它们不会发生巨大变化时,集成是很好的。我们已经做了很多很多次整合。它有助于降低成本,降低功耗。但你是固定的。你与这两个组件的供应商是固定的,你与它们的配置方式是固定的。我们只是觉得,现在还不是整合的时候。”
鉴于 Nvidia 将销售大量“Grace”CPU 和“Hopper”GPU 超级芯片,而 AMD 至少有一个大客户(劳伦斯利弗莫尔国家实验室)购买了大量其“Antares”Instinct MI300A 混合 CPU-GPU 计算引擎, Nvidia 和 AMD 可能将完全不同意这种评估。
也许这样的 XPU 集成不适合英特尔,它必须削减成本并专注于在其核心服务器 CPU 市场上赚钱,就像自 1990 年代末和 2000 年代初 Itanium崩溃以来它一直没有关注的那样。或者更准确地说,可能不适用于 英特尔 CPU 内核和英特尔 GPU 内核。或许 英特尔 CPU 内核和 Nvidia GPU 内核会更受市场欢迎?直到现在,Nvidia 还没有服务器 CPU 业务,所以也许这种潜在合作伙伴关系的时间已经过去,它可能会在“Sapphire Rapids”和一个巨大的HBM3综合体中添加NVLink端口。
无论如何,这不是英特尔第一次考虑在Xeon服务器芯片的X86核心之外使用辅助计算的“frankenchip”设计。这也不是它第一次放弃这些努力。
英特尔于 2014 年 6 月透露混合 CPU-FPGA 设备正在开发中,并于 2016 年 3 月在开放计算峰会上展示了混合 15 核 Broadwell-Arria 10 GX 原型。2018 年 5 月,混合 CPU-FPGA 产品正式推出,CPU 端升级为 20 核 Skylake chiplet,封装的 FPGA为Arria 10 GX 。当然,英特尔多年来一直在单一芯片上销售带有 CPU 和 GPU 的英特尔至强 E3 处理器,但很少谈论集成 GPU 中固有的潜在浮点数学功能——不仅价格低廉,而且基本上免费。英特尔多年前就不再谈论混合 CPU-FPGA 设计,也从未谈论过其低端 CPU-GPU 的可能性,更不用说它如何做一些事情了,比如原定于 2024 年与 Granite Rapids Xeon 一起推出的 Falcon Shores SP。
现在,Falcon Shores多芯片GPU计划在2025年推出,与Granite Rapids的“Clearwater Forest”Xeon SP配套。
McVeigh在ISC23简报会上的路线图演讲中还谈到了一些非常有趣的东西。首先,是路线图:

自 2022 年 5 月以来,英特尔一直在出货 Gaudi2 矩阵数学引擎,这些引擎来自于 2019 年 12 月以 20 亿美元收购 Habana Labs。后续作品 Gaudi3 ,看起来将在 2024 年初问世。
在那之后,当Falcon Shores多芯片GPU在2025年进入路线图时,Gaudi 与Ponte Vecchio 和 Falcon Shores GPU 之间的分界线消失了。如果你有一个具有大量混合精度矩阵算术的NNP和一个具有大规模混合精度矩阵算术的GPU,如果你可以指望Falcon Shores可能具有同等魅力,那么你可能不需要Gaudi 4。尤其是如果你需要像英特尔那样削减削减成本,以实现2023年削减30亿美元成本、2024年和2025年再削减50亿至70亿美元成本的目标。
McVeigh表示,Falcon Shores将同时针对HPC和AI工作负载,升级为HBM3内存,并将“汇集我们Gaudi 产品的精华,其中包括标准以太网交换”和“为规模设计的I/O”。

I/O 看起来像是 CXL over PCI-Express 将 CPU 连接到 Falcon Shores GPU,但如果我们没看错的话,它将使用 Habana Labs 创建的增强版以太网结构将 GPU 连接在一起。(我们很困惑为什么这不会都是 PCI-Express 6.0 ,但话又说回来,由于 PCI-Express 电缆长度和 PCI-Express 上端口数量相对较少,这将仅限于几个机架。 )
Gaudi 1 芯片可以扩展到 128 个与运行 RoCE 的以太网结构互连的设备。每个 Gaudi 1 都有十个 100 Gb/秒以太网端口,你可以在一个节点中放置四个设备或八个设备,并扩展到 32 个节点或 16 个节点以达到 128 个完全互连的节点。Gaudi2 设备可扩展到 24 个以 100 Gb/秒的速度运行的集成以太网端口,这些端口以全对全、非阻塞拓扑将八台设备相互连接:
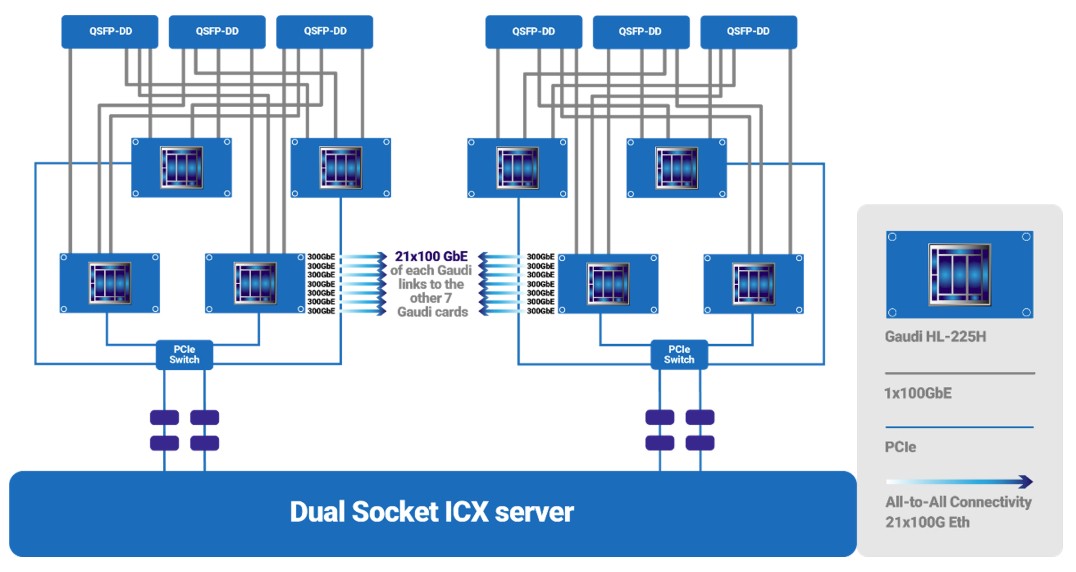
为了创建八路 Gaudi 2 系统,每个设备上的 24 个端口中的 21 个用于在矩阵引擎之间建立全对全链接。每个设备的三个端口以交错方式聚合到总共六个 QSFP-DD 端口,从 Gaudi2 机箱出来,提供互连以扩展 16 或 32 个 Gaudi 外壳,正如我们所说,这是通过常规以太网交换机完成的.
不难想象,这种 Gaudi 以太网结构将升级到 400 Gb/秒甚至 800 Gb/秒的端口,这些端口来自 Falcon Shores GPU,并使用类似的快速以太网交换机将更多设备连接在一起。更令人遗憾的是,英特尔不再拥有以太网交换业务,因为它已经将其收购的 Barefoot Networks 的 Tofino 产品线搁置起来。客户将不得不选择基于 Broadcom、Nvidia、Marvell 或 Cisco Systems 的以太网交换芯片。
看起来英特尔也将从 Gaudi 设备中获取脉动阵列——我们称之为矩阵数学引擎——并使用它们来代替 Ponte Vecchio 设计中使用的 Xe 矩阵数学引擎。所以,是的,不要指望Gaudi 4 是一个独特的产品。
收购Nervana Systems和Habana Labs的23.5亿美元NNP实验到此为止。未来的NNP是英特尔的GPU。唯一会购买 Gaudi2 和 Gaudi3 的公司是那些迫切需要任何矩阵数学功能并且还致力于英特尔未来的 Falcon Shores GPU 的公司。
编辑:芯智讯-林子 编译自:The next platform








