

这是基于英特尔关于Meteor Lake及其客户端策略的 Hot Chips 34 演讲的第二篇文章。我们之前已经介绍了 Meteor Lake,所以这将是一篇关于分类未来的更大的文章。毫无疑问,这是芯片设计的新时代。
英特尔通过 Meteor Lake 进入 Chiplets 和分解的新时代
在 Hot Chips 34 (2022) 上,英特尔讨论了其从为当今大部分细分市场生产的单片芯片到分类未来的历程。
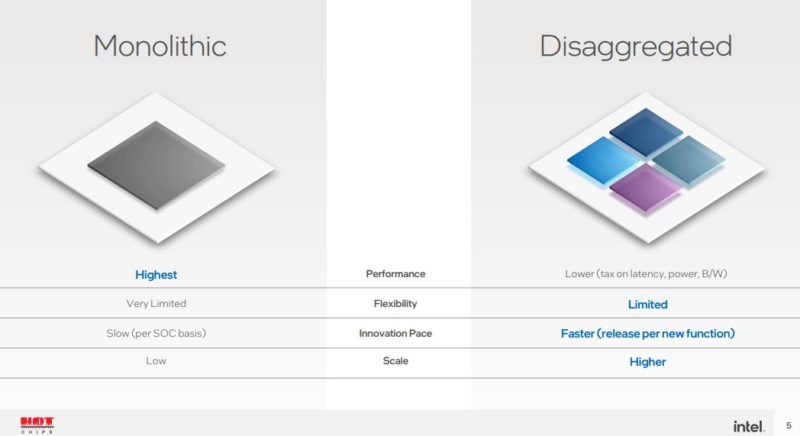
英特尔联合封装芯片已有一段时间了。 英特尔 Ponte Vecchio可能是该公司将 47 个不同的小芯片集成在一个封装中的最佳示例。目前,高端 GPU 可能支持这一点,但在 ASP 低得多的客户端空间中也可能过于复杂。

自从英特尔开始公开采用平铺方法以来,英特尔在消息传递方面一直保持一致的一项内容是,不同的晶体管在不同的工艺上以最佳方式工作。转向小芯片允许英特尔匹配晶体管类型以进行处理。
英特尔还拥有一条跨越 2D 技术和 3D 技术的封装线,例如其 Foveros 线。

在瓷砖中制造消费类设备的部分挑战是英特尔需要大规模制造。这意味着英特尔需要有一个实施成本相对较低的工艺。Foveros 是英特尔在其大部分下一代产品组合中使用的一系列技术。

有许多 Foveros 代,自2018 年架构日讨论以来它已经发展。

下一代为连接提供了更高的密度,但也降低了通过位的功耗。这一点至关重要,因为在多芯片解决方案中,每比特传输的功率(通常表示为 pJ/bit)可能是一笔巨大的成本。省电传输数据是可以重新用于工作的电源。在现代系统中,我们经常会听到这样的轶事,即通过系统移动数据的能力大于用于做有用工作的能力。

虽然 Ponte Vecchio 是我们所看到的处理器的当前高水位线,但英特尔正在为其客户端芯片转向类似但按比例缩小的方法。

虽然我们已经介绍了 Meteor Lake,但我们将使用幻灯片作为正在发生的事情的示例。
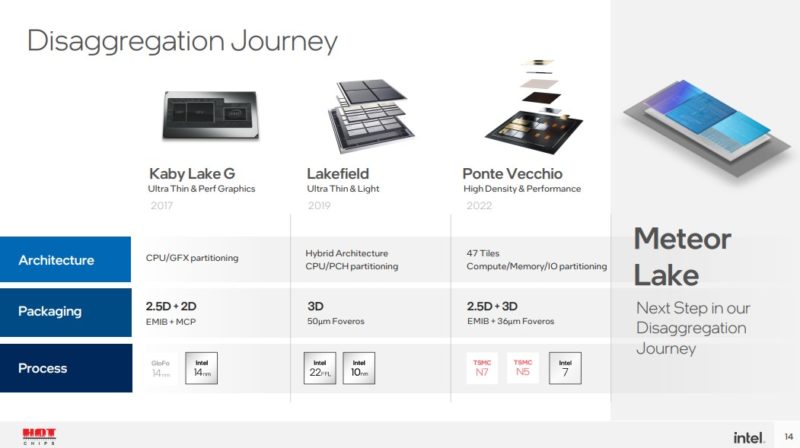
英特尔有一个基础小芯片,可将电源和数据连接传送到上面工作的小芯片。

通过更改为使用此基础芯片的平铺方法,需要权衡取舍。人们提到的第一个是成本。英特尔表示,添加基础裸片的成本被能够使用与最高效工艺对齐的较小裸片所节省的成本所抵消。在 CPU 竞争价格可能有 10 到 20 美元增量的客户空间中,以这种方式制造芯片增加 100 美元是不可行的。
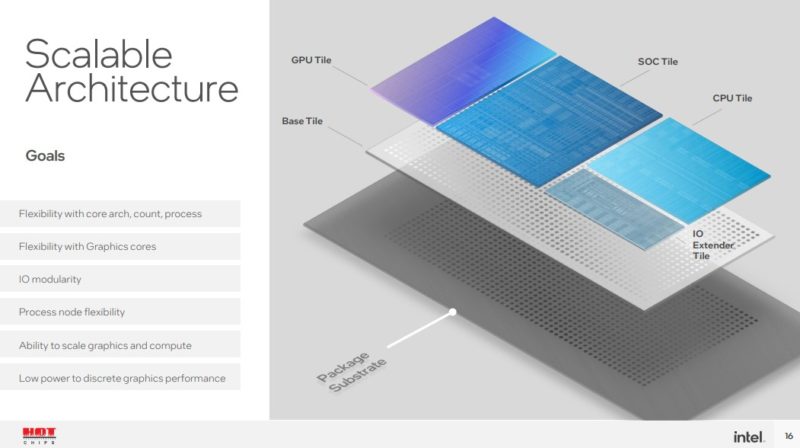
通过这种方法,英特尔可以设计不同的计算块。有些可能有不同的核心数量和核心类型。这些图块也可以有不同的缓存。缓存占用了图块上的大量区域。拥有一个与设备其余部分具有相对标准接口的计算块意味着英特尔可以在新一代内核或新一代工艺节点上进行创新,然后轻松地将它们集成到现有产品中。
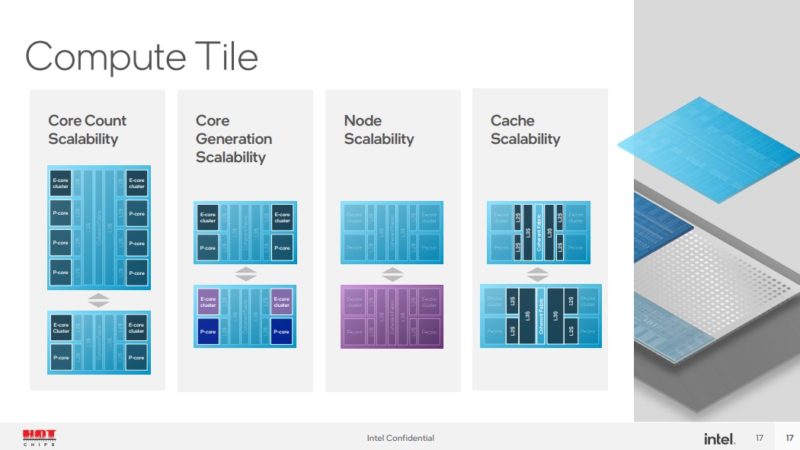
图形块可以类似地随着时间而修改。

SoC 块很有趣,因为英特尔表示显示、成像和媒体比 GPU 块更适合这个块。英特尔没有说的是,一旦有硬件加速器,或者有可能有四个输出的显示器,那么这不一定需要每一代都改变。将跨越多代的功能引入 SoC 意味着英特尔可以集中精力修改 CPU 和 GPU 块,而无需验证显示功能是否适用于未来 GPU 用作示例的新进程节点。
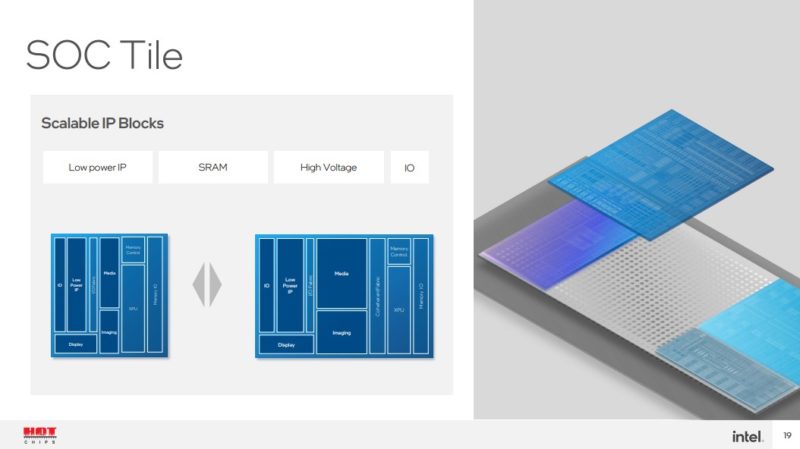
I/O 扩展块可以是很多东西。除了 Meteor Lake 之外,PCIe 通道、USB 通道等功能可以分解成块然后集成。
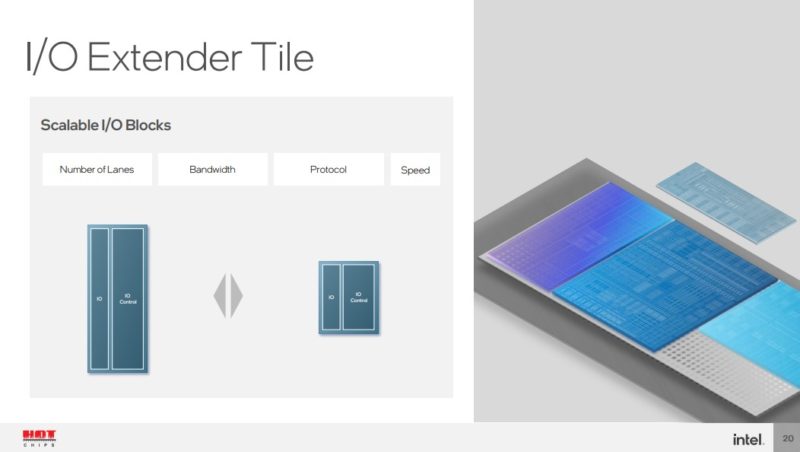
这正是英特尔进行成本讨论的地方。如前所述,在分解方面存在“税”,但英特尔认为它相对较小。
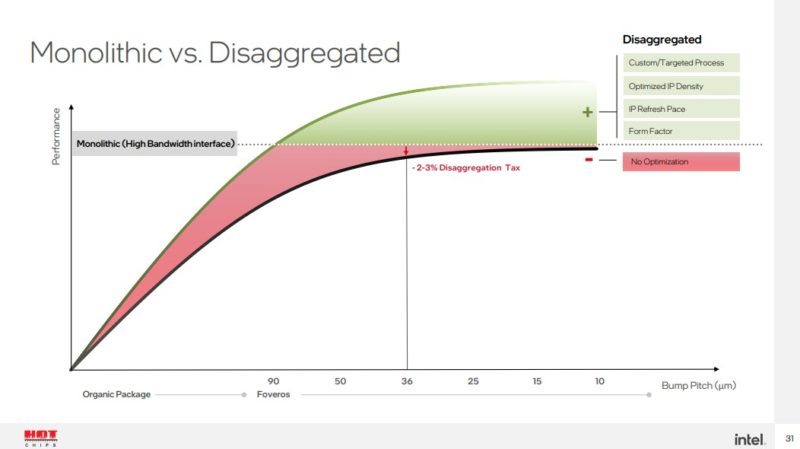
英特尔还认为,通过能够针对不同类型的瓦片针对不同类型的工艺节点,这将有助于抵消分类税。
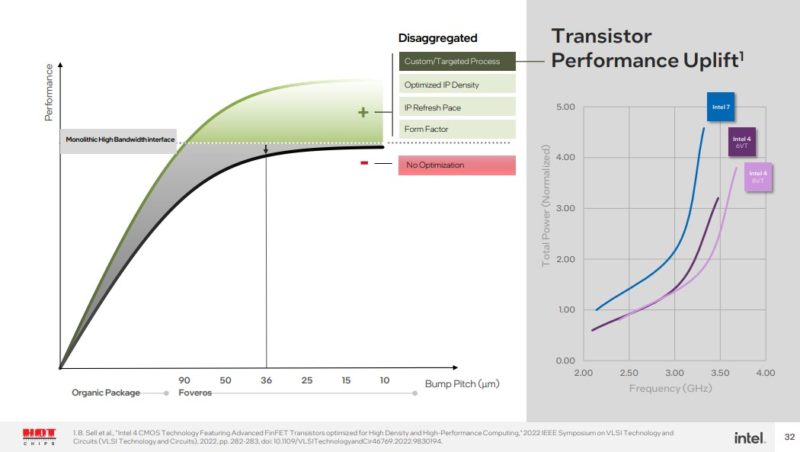
英特尔还认为,能够更快地利用新晶体管,也有助于抵消分类税。
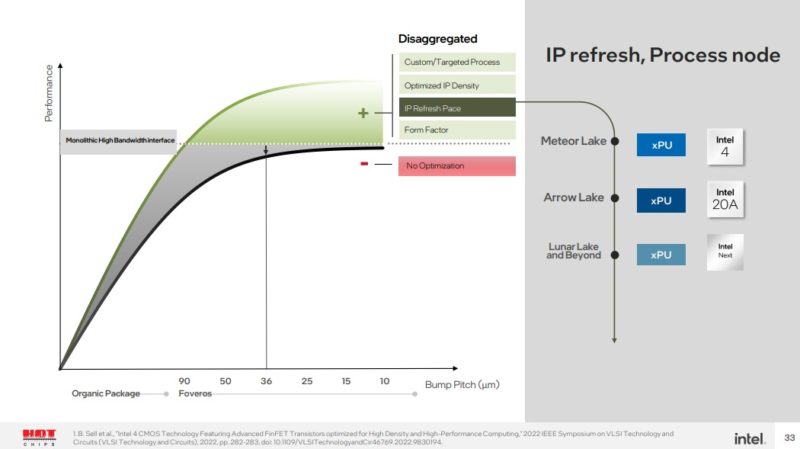
我们将在这里很快注意到,这是一个 36 微米的凸块间距。在 25 微米的 Foveros Direct 水平上,这种分解影响会更小。鉴于此,英特尔没有详细说明 Lunar Lake,但其图表显示了更新后的 Arrow Lake CPU/GPU die,同时保留了 SoC 和 I/O die。Lunar Lake 有所不同,但也许英特尔已经向我们展示了未来。
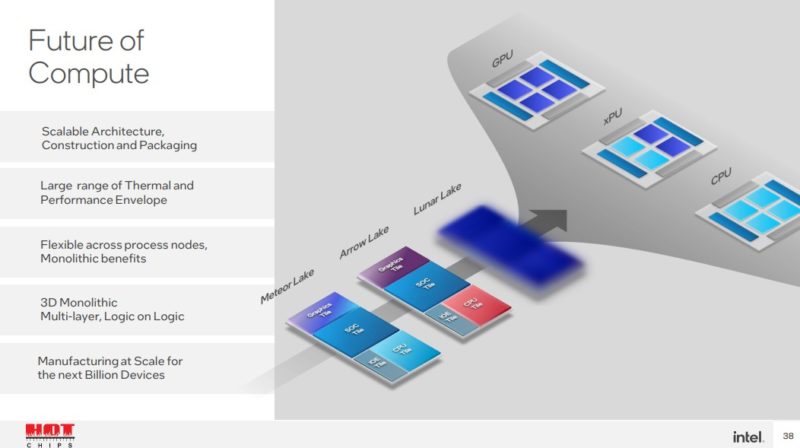
两年前,我们介绍了 SoC 容器化未来的英特尔方法。就像单体应用程序如何迁移到微服务一样,英特尔正在从单体芯片转向更小的块。Meteor Lake/Arrow Lake 看起来很像 2020 年“IP/SOC Methodology Change”时代“Multiple Dies”的演变。CPU 是它自己的 tile,GPU 是它自己的 tile,但 I/O tile 已被分成两部分。

英特尔讨论的下一个演变是将事物分解为单个 IP。然后它可以制造更小的小芯片。通过这样做,它可以在每个 IP 上更快地进行创新。然后,英特尔的产品组需要采用 IP 块,并根据这些 IP 块为不同的细分市场组合芯片。
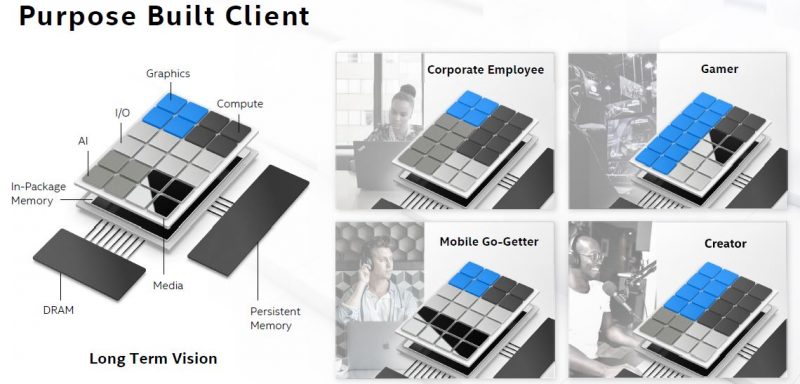
也许更有趣的方面不仅仅是英特尔在上面展示的内容,而是更进一步,看看它的集成工作。该公司发布了 UCIe,该行业正迅速受到关注,以促进小芯片生态系统的发展。

这带来的影响是巨大的。对于消费领域,我们是否会看到更多与 CPU 封装的集成,因为通过 I/O 块添加 I/O(例如更高速的网络、人工智能加速或更多?)在英特尔的产品组合中,这是否意味着Dell Core i9 与 HP 或 Lenovo 的 tile 集成了不同的硅片?
不仅限于供应商本身,这对英特尔未来的运营方式有着巨大的影响。转向平铺方法可能意味着英特尔实际上可以制作高度差异化的解决方案。产品经理不必采用基于消费内核的芯片,然后指定 ECC,并为 Xeon E 系列提供速度和内核数量组合,也许可以选择 P-tiles、E-tiles 、AI-tiles、networking tiles、I/O tiles,所有这些都可能不是来自英特尔。这与产品团队过去实际完成的任务截然不同。
对于市场来说,这将带来新的动力。VPN 设备供应商可能能够获得仅为其机器集成的自定义加密小芯片。HPE 和 Dell EMC 服务器可能使用不同类型的 Xeon。也许戴尔酷睿 i7 将不再在华硕酷睿 i7 中工作(这已经发生在AMD PSB上。)对于 I/O 芯片上的加速器是否有市场特定的要求,使芯片像蓝光一样具有特定的区域?
最后的话
虽然英特尔的 Hot Chips 34 演讲集中在其客户端 Meteor Lake 解决方案上,但更具影响力的含义可能是它对英特尔、业内其他公司和英特尔客户的意义。如果一个真正的小芯片市场发展起来,那么我们获得新创新的速度就会加快。它还可能给我们过去十年或两年所拥有的大部分结构化市场造成混乱。








