
8月25日消息,在近日的Hot Chips大会上,芯片创业公司Untether.AI 展示了其最新的 AI 加速器Boqueria,这是一个拥有1458个RISC-V 核心的AI 加速器,性能高达2PFlops。
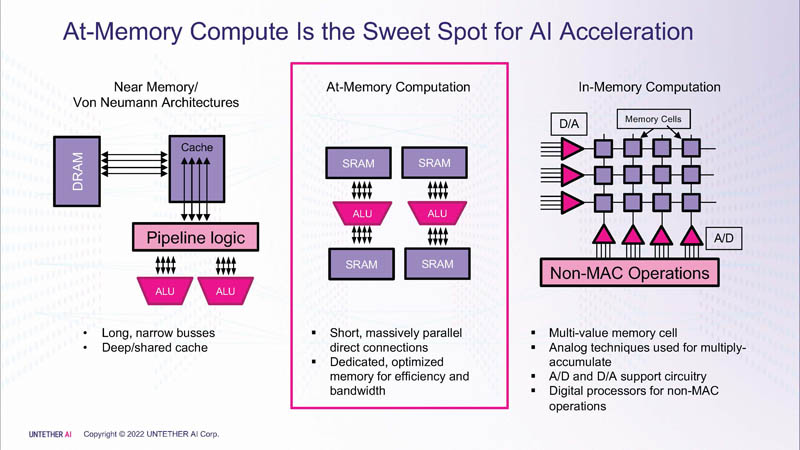
Untether.AI表示,芯片内部的数据移动会带来性能和功耗方面的损耗,所以他们的部分目标是使计算更接近内存,以最大程度地减少数据的移动。
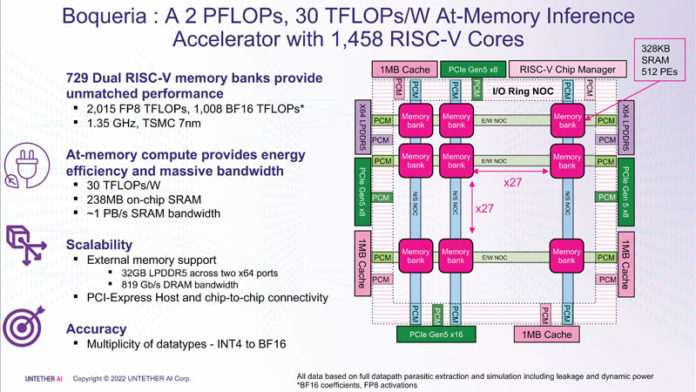
Boqueria 是一款基于台积电 7nm 制程,RISC-V RV32EMC指令集,1458个RISC-V 核心,主频1.35GH,集成了高达238MB 的片上 SRAM ,为芯片提供了大约 1PB/s 的 SRAM 带宽,而且它可以访问外部存储器。FP8 性能可达2015 TFLOPs,BF16性能可达1008 TFLOPs。
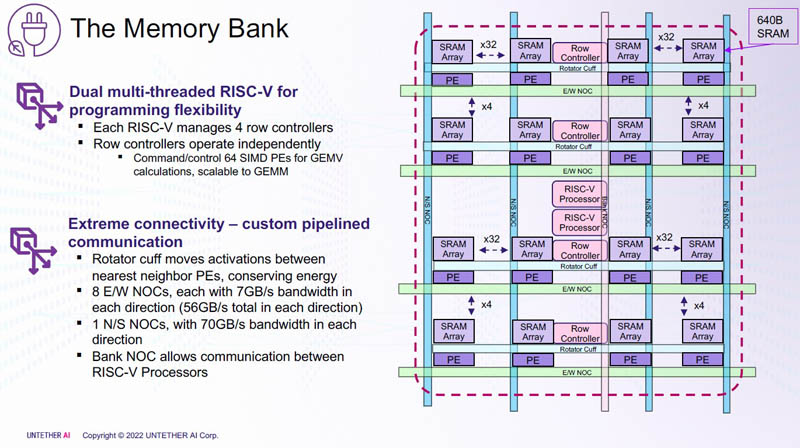
每个内存库(NOC 上的内存/计算集群)都有两个多线程 RISC-V 内核。所有这些存储库都通过 NOC 连接。
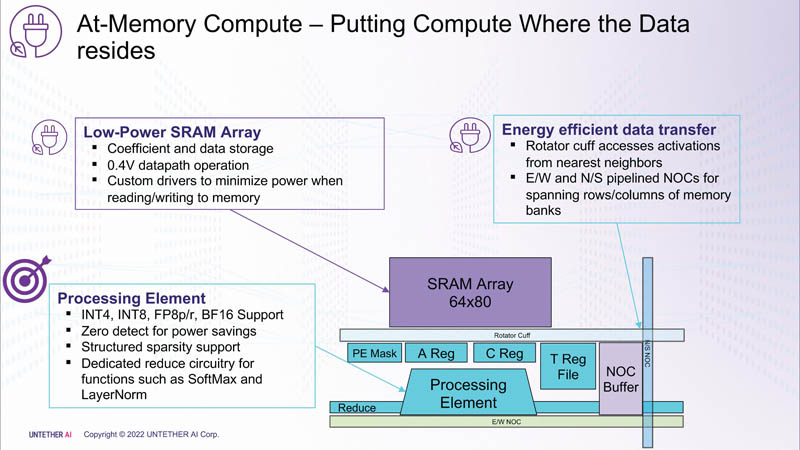
下面这张PPT展示了 Boqueria 如何将 SRAM 和计算结合在一起的。
Untether.AI 的一大见解和设计原则是 FP8 适合推理。他们认为FP8 在设计上比 INT8 更有效。
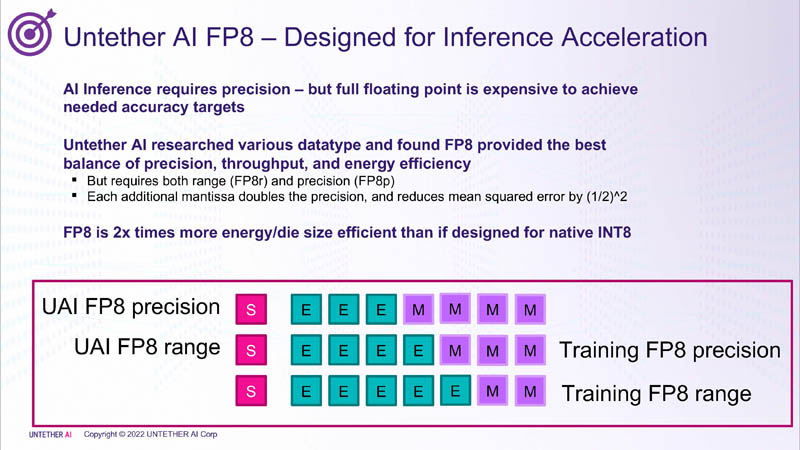
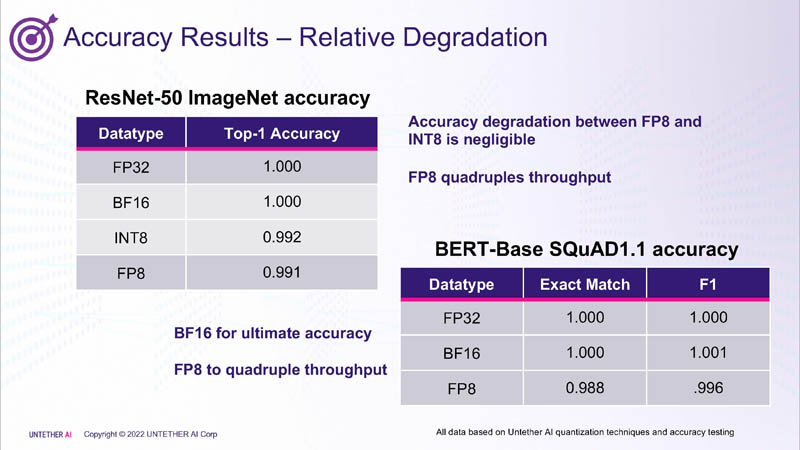
FP8 对推理的准确性影响很小,这就是 Untether.AI 使用 FP8 的原因,因为它更高效且对准确性的影响较小。
Boqueria 的RISC-V 处理器是基于RV32EMC 指令集,并拥有自定义指令。这是 RISC-V 强大功能的一部分。

这是有关片上 NOC 的更多详细信息。

该公司表示,其架构从极低功率扩展到更高功率的设备。它不是在讨论 500W 芯片,而是针对 M.2 类型的功率包络。
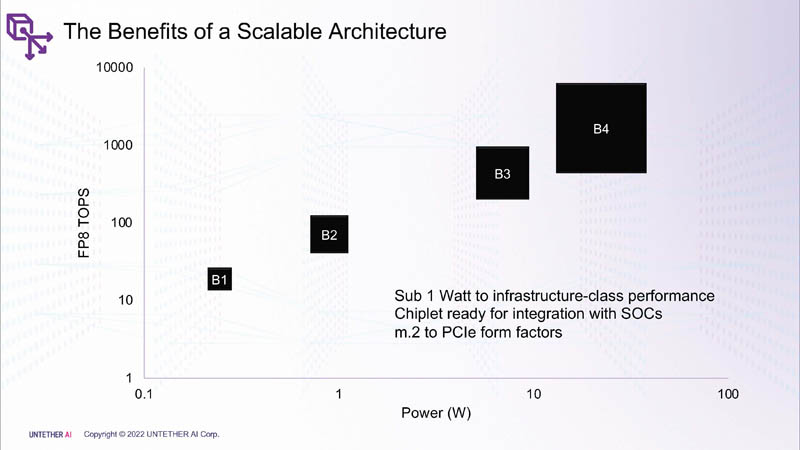
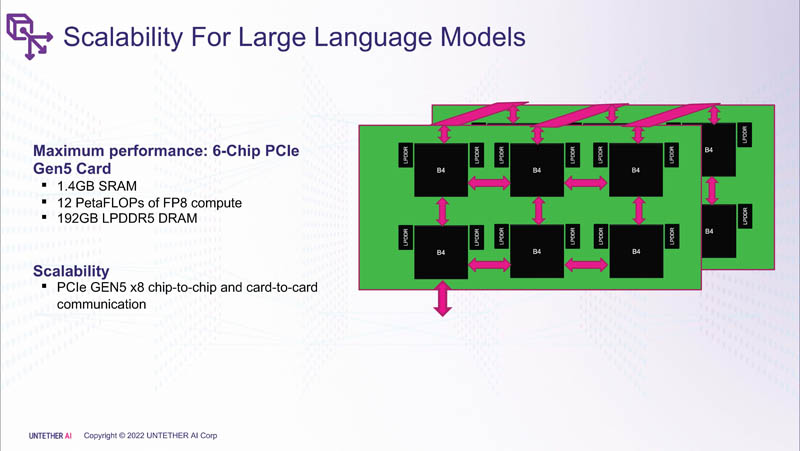
这个想法是然后聚合一些这些较小的芯片以实现更高的性能。请注意,这也是 PCIe Gen5 设备。
该公司的软件称为 imAIgine SDK。
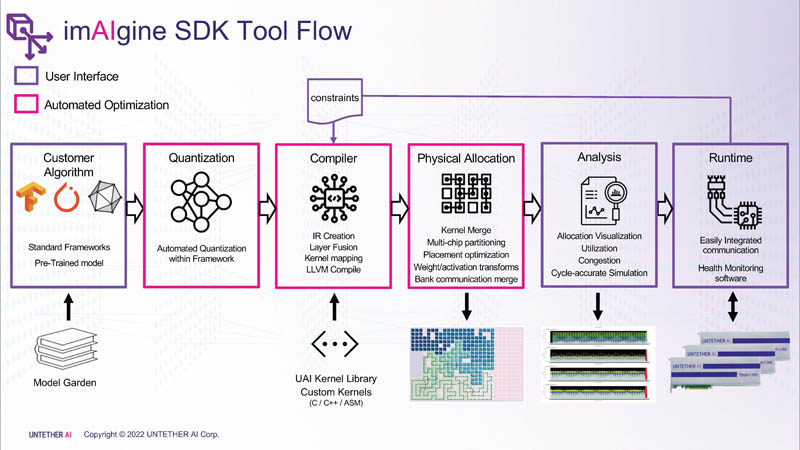
与大多数 AI 加速器一样,编译器需要针对硬件进行高度优化。
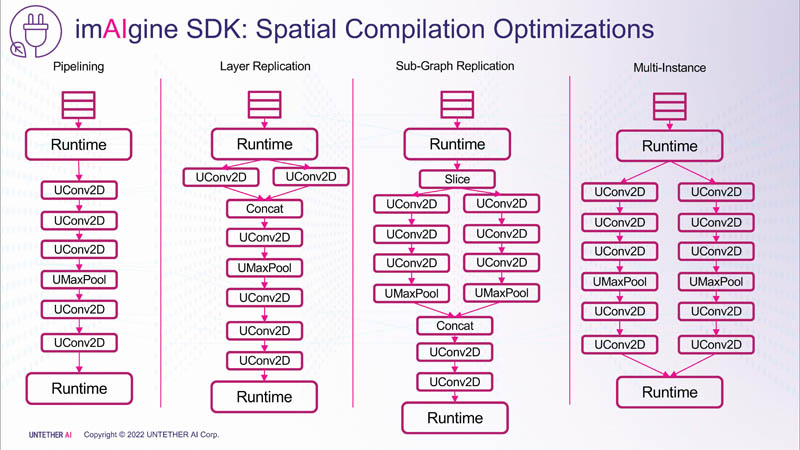
有了这个,该公司表示它可以具有比 GPU 更高的性能。
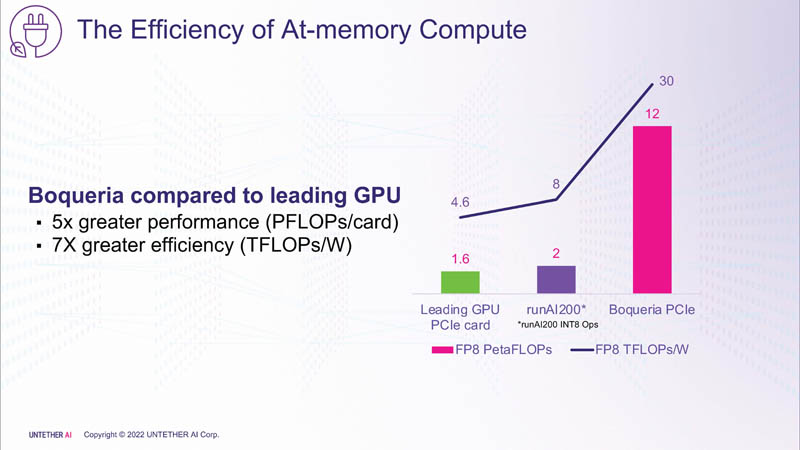
以下是吞吐量和能源效率的比较:

当然,必须记住,被比较的 GPU 是一种更通用的加速器设备,目前已在市场上销售。
最后,每年在 Hot Chips,我们都会看到许多 AI 初创公司。通常,那些试图以更低的价格简单地匹配 NVIDIA 正在做的事情的初创公司,我们不会涵盖。我们认为这很有趣,不仅因为推理加速器角度,还因为它使用的是 RISC-V。这些是 RISC-V 在尝试进入更主流市场之前可以进入 Arm 市场的应用类型。
编辑:芯智讯-林子 来源:servethehome







